之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下:
但是在使用caffe时solver里面一般都用的SGD+momentum,如下:
加上最近看了一篇文章:The Marginal Value of Adaptive Gradient Methods
in Machine Learning文章链接,文中也探讨了在自适应优化算法:AdaGrad, RMSProp, and Adam和SGD算法性能之间的比较和选择,因此在此搬一下结论和感想。
经过本文的实验,得出最重要的结论是:
翻译一下就是自适应优化算法通常都会得到比SGD算法性能更差(经常是差很多)的结果,尽管自适应优化算法在训练时会表现的比较好,因此使用者在使用自适应优化算法时需要慎重考虑!(终于知道为啥CVPR的paper全都用的SGD了,而不是用理论上最diao的Adam)
作者继续给了干货结论:
Our experiments reveal three primary findings.
翻译:
1:用相同数量的超参数来调参,SGD和SGD +momentum 方法性能在测试集上的额误差好于所有的自适应优化算法,尽管有时自适应优化算法在训练集上的loss更小,但是他们在测试集上的loss却依然比SGD方法高,
2:自适应优化算法 在训练前期阶段在训练集上收敛的更快,但是在测试集上这种有点遇到了瓶颈。
3:所有方法需要的迭代次数相同,这就和约定俗成的默认自适应优化算法 需要更少的迭代次数的结论相悖!
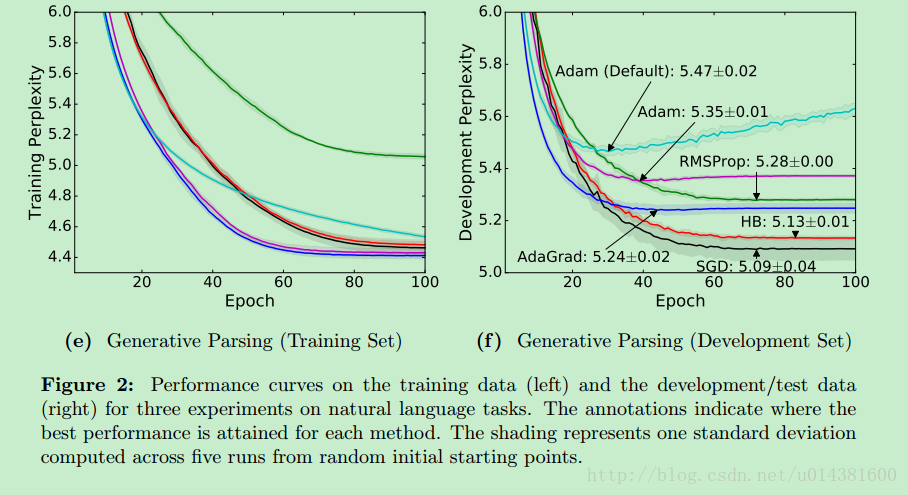
贴几张作者做的实验结果图:
可以看到SGD在训练前期loss下降并不是最快的,但是在test set上的Perplexity 困惑度(这里写链接内容)是最小的。
在tensorflow中使用SGD算法:(参考)
电话:400-123-4567
传 真:+86-123-4567
手 机:13800000000
邮 箱:admin@eyoucms.com
地 址:广东省广州市天河区88号